Abstract
One of the major concerns in the present environment is maintaining privacy. Intruders try to gain access to restricted files or areas thereby hindering privacy. The areas under threat include workstations, data transactions, a forest reserve, and many more. This has led the researchers to come up with what is known as an intrusion detection system (IDS).
Introduction
In today’s internet environment, common authentication techniques, such as ordinary passwords and file security have become inadequate. The report from the article ‘Testing And Evaluating Computer Intrusion Detection Systems’ by Robert Durst et al. suggest that “only 1% and 4% of these attacks will be detected and only about 1% will be reported” (Durst et al. 1999, p.53).
Enterprise web-based services need to exchange a huge amount of information and at the same time have to secure their data from intruders. This cannot be achieved just by enabling a firewall and similar applications. Thus came into being a new security feature called Intrusion detection system. ”An intrusion detection system (IDS) is a security layer to detect ongoing intrusive activities in computer systems and networks” (YU, Tsai & Weigert 2008, p.10). The following nine literature reviews would detail the necessity of intrusion detection by implementing various models. Here we will be seeing several techniques implemented to tackle the issue of intrusion as the common goal.
In the article ‘Delay of Intrusion Detection in Wireless Sensor Networks’ by Olivier Dousse, Christina Tavoularis, and Patrick Thiran, the authors talk about the delay that occurs in the detection of a mobile intruder by the sensors installed in that particular area. In their approach, they assumed the existence of a unique unbounded connected component with a sink. Apart from this, they have also considered the distribution of the nodes to be poison distributed in the spatial domain.
Because of this, the authors were able to do a comparative study on the delay in the detection based on the initial state of the intruder. With the aid of mathematical derivations, the authors established the validity of their assumptions. From this evaluation, they deduced the non-memory less and asymptotic behavior of the intruder. From their observations, the authors established that even the slightest failure in several nodes can result in a total failure of intrusion detection. (Dousse, Tavoularis & Thiran 2006).
The validity of this work was proved in a different environment by Marco Guerriero, Peter Willett, and Joseph Glaz in their article ‘Distributed Target Detection in Sensor Networks Using Scan Statistics’. The procedure followed here is to find out the target with the help of sensors in a two-dimensional region. This is mainly a tool used for intrusion detection, which is emerged from the statistics field. The three ideas introduced in this are “two-dimensional MA-based sequential procedure for detecting and localizing the target, counting only binary detection level sensor data, and testing for any spatial inhomogeneity” (Guerriero, Willett & Glaz 2009, p.2629).
The tool used in this is scan statistics. The scan statistic will look for the detection. At the time of observation, this will test the events or detection occurring in the window.
The diagram shows the scanning of the unit interval within a window.
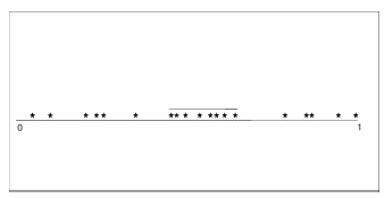
The bar, which is visible inside the window, shows the total number of events present, and the dots above the bar show the events. The next picture gives some more idea regarding this.
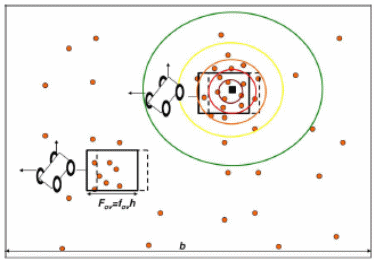
In this, the target is detected with the help of randomly deployed sensors. The red dots present in this are the sensor and the black square is the targeted area. The targeted area can be detected with the help of sensors. This can happen because it tends to sense magnetic disturbance, which comes from the remote radio source. “A MA “drags” a sliding window around the area, and if the number of reporting sensors that are encompassed exceeds a threshold level that is determined by scan-statistic theory, detection is declared” (Guerriero, Willett & Glaz 2009, p.2630).
All kinds of analysis and simulations take place with the help of mathematical and statistical formulas. All kinds of statistics or settings have been done with the assistance of Bernoulli and poison.
The above description was based on scan statistics in two dimensional domains across an area of interest by a mobile agent. These studies are conducted in a physical environment. Looking at the field of computer networks, several researches have been done on similar grounds to detect intrusion. In the article ‘Description of Bad-Signatures for Network Intrusion Detection by Michael Hilker and Christoph Schommer deals with the intrusion in networks using a similar strategy. They adopted a technique that involved pattern matching. A data structure is created which stores the details of bad packets designated as intrusions.
Any incoming packet is compared with this database to check if the packet’s signature matches that of the bad packets. In their research work, they have used a standard called ANIMA. “ANIMA stores bad-signatures of intrusions in directed and weighted graphs as well as returns for each checked-packet a value how malicious the packet is” (Hilker & Schommer 2006, p.1). It has a data structure that continuously updates itself with the latest intrusions online. It has an advantage over other software available in the market, i.e. it adapts faster to intrusions, saves a considerable amount of memory space, and is tolerant to good packets.
It is also capable of removing mutated strings of bad signatures. We can see that the authors have not approached a usual rule-based approach to detect intrusions within the system. This is a kind of application that resides between the firewall and the outside network and hence is capable of removing the intrusion well before it can create any damage to the system files. But as discussed in the beginning, this approach is very simple and hence is not that efficient as other intrusion detection systems which use much more sophisticated algorithms.
This application will result in overloading of CPU cycles if the signature to be checked is huge. This has forced us to focus on other concepts such as the one discussed in the article ‘Cluster-based novel concept detection in data streams applied to intrusion detection in computer networks’ by Eduardo J. Spinosa, Andre Ponce de Leon F. de Carvalho, and Joao Gama where the authors use an algorithm called OLINDDA (Online Novelty and Drift Detection Algorithm) which is capable of handling huge traffic. “In this paper, a cluster-based novelty detection technique capable of dealing with a large amount of data is presented and evaluated in the context of intrusion detection”. (Spinosa, de Carvalho, & Gama n.d., p.976).
The authors approached the issue by dividing the work into two phases – supervised and unsupervised. They incorporated the algorithm into three models namely normal, extended, and novelty. In the supervised phase, the system was brought under normal traffic which was free of any intrusions. In the nonsupervised model, the coordinates of the sample were checked if it lies within the hypersphere of any of the existing models. If yes, the statistics are updated and then the sample is discarded to save the memory. If it doesn’t match, the sample is moved to a short-term memory location, FIFO. With the usage of simulations like LabPurity and ValClPurity, the authors concluded that the validity of the so formed cluster remained the same from their point of discovery. This supported the authors’ theory that cluster-based novel detection is capable of handling a larger amount of data than the previously existing IDs.
Till now we have seen different approaches to detect intrusion detection. But, all these techniques were carried out outside the host, and hence the host had no control. From hereon, we will be discussing some of the approaches that deal with the host and user. To start with, let us see the article ‘ADMIT: Anomaly-based data mining for intrusion’ by Karlton Sequeira and Mohammed Zaki. The article deals with a problem caused by masqueraders and factual users in the computer terminal and the solution to these problems.
It discusses how to stop these intruders by proposing a system called ADMIT (Anomaly-based Data Mining for Intrusion). The advantage of using anomaly-based methods is that it has got a tendency to notice the new attack. It is based on real-time intrusion detection, data collection and processing has been done on the host side. The main feature of this is it has got a continuously running program that can create the profile of the user and verify the data. The concept could be well understood from the architecture of ADMIT given below:
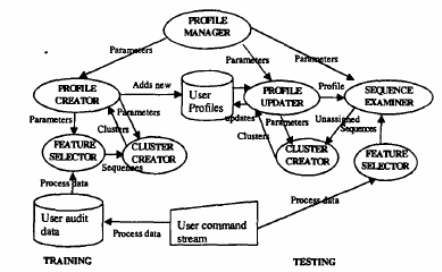
At startup, the initialization of profile creator, profile updater, and sequence examiner is done by the profile manager. Profile creator tells feature selector what kind of data to parse and feature selector must make a sequence of tokens. Initializing of cluster creator is done by profile manager and it is cluster creator who converts sequence into clusters. These things are all done at training time.
At the time of testing, the feature selector parses, cleans, and tokenizes details of the user into the sequence. The sequences obtained from this are matched with the profile which is obtained from the pool of user-profiles which is created by the profile updater. Each of these is sent to a security analyst.
The evaluation of this system has been done on its accuracy of the system, efficiency, and usability. These things are analyzed by analyzing detection rate and by false-positive rate. The advantage mentioned by authors of this paper about this system is it requires only a short training time and it is better suited in real time. These techniques discussed above can only notify the user regarding the intrusion and doesn’t provide detailed information of the changes made by the intruder. We now see a technique that would provide us with this information. For this, we will be referring to the article ‘Backtracking intrusions’ written by Samuel T. King and Peter M. Chen. “The goal of BackTracker is to identify automatically the potential sequences of steps that occurred in an intrusion”. (King & Chen 2005, p.51).
The advantage of using this system is that it can detect the problem from the initial stage itself and it can identify the files and different types of processes that affect and from there it can identify the different types of events occurring in chain model. With this, one can analyze different types of problems or real-time attacks in the system. Backtracking method helps the administrator to know clearly about the activity taking place during the attack.
Backtracker finds the chain of information by logging the system call. For validating this approach, the author utilized the honey pot machine. With the aid of trace attack and bind attack, they evaluated the features that needed to be incorporated into the backtracking mechanism. This backtracking mechanism has another major advantage that it is capable of repairing files that have been corrupted by the intrusion using the repairable file service. All these techniques seldom involve the user. Certain files which resemble intrusions but which are harmless to the system can cause false alarms putting the system in a confused state.
We now see a technique based on fuzzy logic to decide whether an alarm is valid or not. This concept is briefed in the article ‘An Adaptive Automatically Tuning Intrusion Detection System’ prepared by Zhenwei YU, Jeffrey J. P. Tsai, and Thomas Weigert. The system presented here is an intrusion detection technique that tunes automatically. “This manual tuning process relies on the system operators to work out the updated tuning solution and to integrate it into the detection model”. (YU, Tsai & Weigert 2008, p.10).
When any kind of intrusion is detected in the system then it is reported to the system administrator as an alarm. What the system administrator will do is that he will verify the data and mark the false prediction. Then this will be fed to the system. The system will automatically tune the feedback. The main problem with this is generating a false alarm and putting the administrator in trouble. To overcome this, one solution has been formulated and it is called ADAT which is called automatically tuning intrusion detection system. In this system, a filter has been pushed into the system. The thing is the administrator can control the volume of the filter.
To adapt to the situation, that is, for opting out and in, the system uses the fuzzy method. This concept was verified by letting a user decide on the level of intrusion by grading it as true or false. According to this, the user grades a total of 100 samples as false alarms out of the 400 indications. This has shown that very little burden is put on the user. The success of this system also depends on the user’s knowledge of the intrusion. Another approach that allowed user control over intrusion detection is ‘A user-centered approach to visualizing network traffic for intrusion detection John R. Goodall, A. Ant Ozok, Wayne G. Lutters, Penny Rheingans and Anita Komlodi.
In this approach, the user is provided with a visualization of both the high-level and detailed patterns that would help the user to determine the intrusions. “The tool presents analysts with both ‘at a glance’ understanding of network activity, and low-level network link details” (Goodall et al. 2005, p.1403).
The visualization tool used here by the authors was TNV (Time-based Network traffic Visualization). The pattern included details regarding the IP and port numbers. The display used time as a dimension for analysis and displayed the packets that were generated at any particular time. If the traffic is found to be near-constant, then we can consider the action to be that of interactive login. The one with sporadic response was found to be between client-server requests. For verifying its usage, 12 undergraduates were briefed about the usage of the application and given the task of detecting the intrusions. With the aid of the TNV tool, the students were able to successfully predict the regions of unexpected behaviour and the source responsible. In short, this tool helped in providing a detailed inspection of both network link and network state information which is crucial in ID analysis.
Summary
Through this literature review, we have managed to research on nine articles that gave us an insight into the importance of intrusion detection in various fields. We saw the approaches taken by several authors invalidating their theories regarding intrusion detection, using models, experimental setups, mathematical modeling, etc. We have seen the advantages and disadvantages of every model and this has helped us in a better understanding of the nature of intrusion in various environments
Conclusion and future improvements
The study of the nine articles has given an insight into the various fields where intrusion detection is necessary and how it can be deployed with the technologies available. The possibilities for advancement in this particular field are very high because of the interest shown by the government organizations and industries.
Reference List
Dousse, O, Tavoularis, C, & Thiran, P 2006, Delay of intrusion detection in wireless sensor networks, ACM.
Durst, R, Champion, T, Witten, B, Miller, E, & Spagnuolo, L 1999, Testing and evaluating computer intrusion detection systems, Communications of the ACM, vol.42, no.7, pp.53-61.
Goodall, JR, Ozok, AA, Lutters, WG, Rheingans, P, & Komlodi, A 2005, A user-centered approach to visualizing network traffic for intrusion detection: abstract, CHI: Late Breaking Results: Posters.
Guerriero, M, Willett, P, & Glaz, J 2009, Distributed target detection in sensor networks using scan statistics: introduction, IEEE Transactions on Signal Processing, vol.57, no.7, pp.2629-2639.
Hilker, M & Schommer, C 2006, Description of bad-signatures for network intrusion detection: abstract, Australian Computer Society, Inc.
King, ST & Chen, PM 2005, Backtracking intrusions, ACM transactions on Computer Systems, vol.23, no.1, pp. 51-76.
Sequeira, K & Zaki, M 2002, ADMIT anomaly-based data mining for intrusions, ACM.
Spinosa, EJ, de Carvalho, AP de LF, Gama, J n.d., Cluster-based novel concept detection in data streams applied to intrusion detection in computer networks: abstract.
YU, Z, Tsai, JJP, & Weigert, T 2008, An adaptive automatically tuning intrusion detection system, ACM Transactions on Autonomous and Adaptive Systems, vol.3, no.3, pp.10:1-10:25.