Executive summary
The main aim of the study was to explore the important ranges of intelligent language tutoring systems. The aim of the system is to formulate the natural language processing systems that aim at teaching and assessing the capability of the students. The utilization of the intelligent language tutoring systems in instruction makes it simple to analyse the leaner’s mistake and provide beneficial input and eliminate the sources of errors.
For the drive of this paper, where the main attention was the intelligent language tutoring systems, picking confused investigation of the learner’s data may provoke misguided determination of slip-ups or issuing of criticisms. There are unique languages tutoring systems that have been described in this paper. Since learning any new language is a challenging assignment, the role of this paper is therefore, to provide the new insights of intelligent language tutoring systems that eliminate the challenges. To the best of the paper’s interest, the intelligent language tutoring systems have not yet been overviewed widely; this has provided the framework to lead this study.
Introduction
These days, PCs play a big role in our daily activities. PC applications have turned out to be generally utilized as a part of various areas to give valuable services to their clients. Illustrations of tutoring applications which discover the functionalities of PCs into their designs are lesson mentoring, language testing and correcting mistakes (Chowdhury 2003).
These are great reasons that empower analysts and engineers to consider planning the ITSs (Intelligent Tutoring Systems). These frameworks endeavour to imitate the personalized human tutor keeping in mind the end goal to convey learning the material on the internet as opposed to utilizing books and customary learning environment. An example of artificial intelligence field is the NLP (Natural Language Processing). It assumes a huge part in how PCs could decipher and prepare human natural dialects (content or discourse) keeping in mind the end goal to create valuable learning applications (D’Mello & Graesser 2013).
The intelligent language tutoring systems can be improved by using the Auto-tutor. It is a PC tutor that mirrors the course plans and teaching procedures of a genuine human aide by a method for a dialog with the student using the normal dialect. This was accomplished by a group of specialists who were exploring the same subject matter. The specialists taught the students about the PC capability course. Auto-tutor or auto-coach has been made in progressive stages, where the most recent have a 3D interface and has been realized using an advanced visual framework (Heift & Rimrott 2008).
Auto-coach requests from the learner a few test addresses that require a segment of right answers. Each request in the Auto-coach is associated with a particular game plan of longings (impeccable replies) and misinformed judgments (wrong answers) that are secured in an instructive projects script. A great examination opportunity could be developed from this paper which is building an Arabic online intelligent language tutoring systems for showing Arabic dialect for non-local speakers with a specific end goal to come to a more extensive scope of individuals over the web.
All of the intelligent language tutoring systems that consolidated a dialog with learner has been incorporated in English when contrasted with different dialects. It is valuable to fuse other hard to learn dialects, for example, Arabic, keeping in mind the end goal to investigate more in the dialects’ components while managing the learner.
The auto-tutor has been customized to have the ability to alter the misinformed judgments and give appropriate information to the students (Heift & Rimrott 2008). For the Auto-tutor to be prepared for surveying the answers of the students and match it with the interests and misinterpretations, the dormant semantic investigation has been utilized as the case planning system. In any case, a vocabulary syntactic system is moreover used as a part of a solicitation to overcome the hindrances of inert semantic examination by a method for considering syntactic information while evaluating the answers of the students (Yassine, Paolo &José-Miguel 2007).
This study sought to reveal the understanding of intelligent language tutoring systems. The systems attempts to create NLP systems that focus on training and evaluating the student’s abilities. The utilization of intelligent language tutoring systems in instruction makes it simple to analyse the leaner’s error and provide benefits to the students by alleviating the sources of mistakes. It ought to be noticed that authoring systems are different from intelligent language tutoring systems as they simply empower the author to speak his information in common dialect without depending on any intelligent programming. To the best of the paper’s interest, intelligent language tutoring systems have not yet been overviewed widely, which has spurred to lead this study (Farghaly & Shaalan 2009).
The natural language processing has been advanced rapidly; a wide variety of uses have been created in many spaces, for instance, information recovery, data mining, machine translation, transcript to dialogue, and tutoring systems (which is the primary objective of this paper). In line with the natural language processing framework, researchers must consider the difficulties and qualities of the language, for example, an uncertainty which is a noteworthy issue in enhancing that needs to be comprehended when creating the natural language processing frameworks (Monz & de Rijke 2001). For the sake of this paper, where we are worried about intelligent language tutoring systems, picking mistaken examination of the learner’s information may prompt off base determination of mistakes or issuing of feedbacks.
Problem definition
ITSs (Intelligent Tutoring Systems) recreate the personalized human tutor for conveying information intelligently rather than utilizing books and the conventional learning environment. To consider the most learning results, ITSs have joined a few strategies, for example, mistake recognizable proof and rectification and building reliable clarifications through coordinating procedures of intellectual science and artificial intelligence (Jung & VanLehn 2010). The CAI (Computer-Assisted Instruction) is very much dissimilar to the ITSs. This is due to the fact that the ITSs can think naturally and generate the necessary feedback. Diverse mentoring frameworks have been executed to cover diverse languages, for example, English, Arabic, Chinese, German and numerous others (Monz & de Rijke 2001).
NLP (Natural Language Processing) is an area of examination that spotlights on how PCs translate and prepare the human characteristic language (content or discourse) with a specific end goal to perform helpful applications (Monz & de Rijke 2001). NLP has been emphasized to incorporate NLU (Natural Language Understanding) and NLG (Natural Language Generation).
There are different NLP assignments that have been investigated by numerous analysts. These assignments could incorporate but certainly not restricted to grammatical tagger, tokenization, division, curtailing and deconstructing. All things considered, so as to process and investigate the accessible much content, NLP abilities and skill are required (Yassine, Paolo & José-Miguel 2007).
The NLP method that processes the likeness in the middle of any two sections of content (a word, sentence, passage or record) is called the LSA (Latent Semantic Analysis). Furthermore, it is a system for inferring connections of expected logical utilization of words in a dialog examination. LSA can separate different understudies’ levels (great, dubious and wrong). Etymological (for instance, what has been composed precisely) and semantical (for instance, what was expected) levels are one of the primary trials in NLP frameworks.
Case in point, a few words have various utilizations in different connections, while numerous words could have comparable significance; where LSA could deal with these issues. Really, LSA has a couple of hindrances, for instance, the inability to see refutation, encoding the set of words, nor unequivocally make sense of what is being off course in the wrong response in the midst of the dialog between the student and the Auto-Tutor (Acosta & Anja 2015).
Nerbonne (2003) has proposed for a standard based intelligent language tutoring systems with a specific end goal to portion singular names from the Arabic subject. He likewise used an Arabic morphological analyser amid the period spent separating the title components. He utilized a part of the control resources in the system, which is a component of the application (Rosa & Leow 2004). In the subsequent studies, a few analysts do not use any gazetteers in their structure and rely rather on courses of action that assist in discovering singular names in the expressions and on the morphological analyser yield as well (Nagata & Swisher 2005). Peters, Weinberg and Sarma (2009) differentiated their system and the Arabic-based intelligent language tutoring systems structure that utilizes singular names gazetteer instead of the dialect structure. The results exhibit that the proposed system beats the other structure with F-measure of above 90%.
Entailment can refer to the errand of choosing whether the significance of two bits of content is involved to each other (i.e. one alludes to the next). Entailment has been included in different applications, for example, recovery of information, machine interpretation and tutoring systems. The assessment of the feedbacks generated by the students forms a critical component of entailment (Farghaly & Shaalan 2009). At the point when the auto-tutor suggests a conversation starter to the understudy, there are a few settled desires (i.e. right replies) which relate to that question. Entailment takes a shot at choosing whether the understudy’s information content (i.e. the understudy’s answer) will coordinate those desires (Yazdani 2016).
Related work
The intelligent language tutoring systems is a system that pays consideration on the basic dialect of the student and can effectively extend the profitability by means of copying the learning shapes. Joining the NLP methodologies into an intelligent language tutoring systems will give appropriate strategies to evaluate the students’ answers by perceiving the substance data mistakes and give brief information to them. Around there, we discuss different intelligent language tutoring systems frameworks that have been completed in different spaces in different dialects (Jung &VanLehn 2010). Yazdani (2016) has suggested for a principle based intelligent language tutoring systems framework in order to excerpt individual names from Arabic content.
They also utilized an Arabic morphological analyser during the time spent extracting the title elements. They used a portion of the handling assets in the framework, which is a piece of the application (Yassine, Paolo & José-Miguel 2007). In the recent studies, some researchers do not utilize any gazetteers in their framework and depend rather on arrangements of important words that aide in finding individual names in the phrases and on the morphological analyser yield too (Yassine, Paolo & José-Miguel 2007). Farghaly and Shaalan (2009) contrasted their framework and Arabic based intelligent language tutoring systems framework that uses individual names gazetteer other than the language structure. The outcomes demonstrate that the proposed framework beats the other framework with F-measure of 90%.
There is an outline of intelligent language tutoring systems in light of SVM (Support Vector Machine) technique to deal with the Arabic reports (Farghaly & Shaalan 2009). The researchers have focused on the impacts of four sorts of elements on the execution of the intelligent language tutoring systems framework when the directed dialect is Arabic. The sorts of elements are circumstantial components, lexical elements, morphological elements, and syntactic elements. The estimations of these components are spoken to by a vector for every word notwithstanding its class. The led tests demonstrate that taking to account the four elements together by the framework prompts the most elevated results with F-score of over 80%. As per the trial investigation, the morphological highlights importantly affect the execution of an Arabic intelligent language tutoring systems framework (D’Mello & Graesser 2013).
Chowdhury (2003) has directed an assessment between three administered learning methods that are utilized for the Arabic intelligent language tutoring systems. The three procedures are the support vector machine, maximum entropy, and conditional random field. He also researched the impact of elements determination and learning calculations choice on the execution of an Arabic intelligent language tutoring systems framework. The outcomes demonstrate that applying the conditional random field strategy utilizing an arrangement of 15 components, which incorporates morphological and lexical highlights among different elements, accomplishes the most astounding F-measure of over 83%.
Parts of Arabic Language
The Arabic Language can be reflected as both essential (because of the Arabic society, history and legacy) and testing (because of its morphological and syntactic unpredictability). Arabic is a Semitic language and is talked by more than 300 million individuals across the world. Discretization assumes a vital part inappropriately proclaiming and disambiguating Arabic words (D’Mello & Graesser 2013).
Arabic language being used has been sorted into three categories. The first category is the traditional Arabic or qur’anic Arabic. It is the recognized form that had been utilized for a long time as the dialect of Islam. The second category is the modern standard Arabic. It is the dialect utilized by media and training in learning institutions. Finally, the third category is the colloquial Arabic. It is the casual day by day talked dialect by the Arabs (Jung & VanLehn 2010).
Arabic natural language processing has been developed quickly; a lot of utilizations have been produced in various spaces, for example, information recovery, data mining, machine translation, transcript to dialogue, and tutoring systems (which is the fundamental centre of this paper). To the extent Arabic is concerned, scholars must consider the difficulties and qualities of the language, for example, an uncertainty which is a noteworthy issue in enhancing that needs to be comprehended when creating Arabic natural language processing frameworks (Monz & de Rijke 2001). For our situation, where we are worried about intelligent language tutoring systems, picking mistaken examination of the learner’s information may prompt off base determination of mistakes or issuing of feedbacks.
Endeavours in developing intelligent language tutoring systems
Intelligent language tutoring systems are frameworks that attention on the common language of the learner and can successfully expand the productivity via imitating the learning forms. Joining natural language processing strategies into intelligent language tutoring systems will give proper techniques to assess understudies’ answers by recognizing the content info mistakes and give a prompt input to them. In this area, we talk about various intelligent language tutoring systems that have been actualized in various spaces in various languages (Yassine, Paolo & José-Miguel 2007.).
Improvement of Intelligent Language Tutoring Systems
The intelligent dialect teaching frameworks is a system that pays thought on the essential lingo of the understudy and can viably broaden the gainfulness by a method for duplicating the learning shapes. Combining the NLP philosophies into ILTS frameworks will give suitable techniques to assess the answers of the learners by seeing the substance information mix-ups and give brief data to them. Around there, we examine diverse shrewd dialect mentoring frameworks systems that have been finished in various spaces in various vernaculars. Numerous researchers have recommended for a rule based ILTS keeping in mind the end goal to extract singular names from the Arabic substance.
The astute mentoring frameworks reproduce the customized human guide for passing on data keenly as opposed to using books and the routine learning environment. To consider the most learning results, the intelligent tutoring systems have joined a couple of methodologies, for instance, mistake recognizable evidence and amendment and building solid illuminations through organizing strategies of scholarly science and artificial intelligence. The PC-mediated direction is particularly not at all like the intelligent tutoring systems. This is because of the way that the intelligent tutoring systems can think normally and produce the vital input.
Auto-tutor is a PC mentor that mirrors the course designs and training strategies of a real human guide by means of a dialog with the learner utilizing the natural language. This was achieved by a team of researchers based at the University of Memphis. The researchers taught the students about the computer proficiency course. Auto-tutor has been created in successive stages, where the last has a 3D intelligent interface and has been actualized utilizing visual NET and C++. Auto-tutor solicits from the learner a couple of testing addresses that require a section of right replies. Every inquiry in the Auto-tutor is connected with a specific arrangement of desires (perfect answers) and misguided judgments (wrong replies) that are put away in an educational programs script.
Auto-tutor has been programmed to have the capacity to adjust the misguided judgments and give a proper input to the learner. For the Auto-tutor to be equipped for assessing the learners’ answers and equal it with the desires and misinterpretations, latent semantic analysis has been used as the example coordinating strategy. Be that as it may, a lexicon-syntactic procedure is likewise utilized as a part of a request to conquer the impediments of latent semantic analysis by means of considering syntactic data while assessing learners’ answers (Jung & VanLehn 2010).
Electronic intelligent language tutoring systems in German tutor was introduced as an intelligent language tutoring system that has been built to frame the sentence structure improvement for conveying a course in German by means of an online domain (Yassine, Paolo & José-Miguel 2007). The understudy model is included for keeping up every one of the learners’ profiles and gives understudies versatile input that is suited to their mastery alongside some proposed works out. Productivity has been achieved through the powerful plan of the framework, as demonstrated in Figure 3.1, where the web-server cooperates with the customer, through Java and CGI scripts, while clever and versatile systems were based on the different server side where the response is prepared (Yazdani 2016).
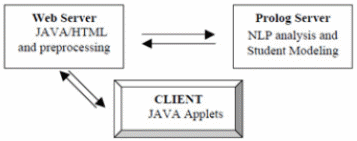
Methodology
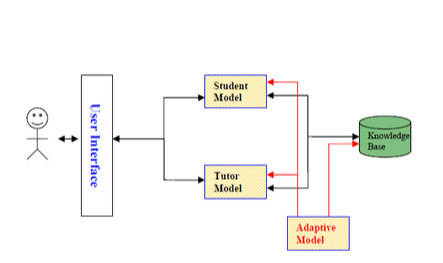
The main aim of this paper was to explore the execution of a principle based intelligent language tutoring systems framework and a measurable based framework for Arabic dialect. A number of the training resources use languages in making the principles and it is created within the intelligent language tutoring systems (Miller 2000). Figure 4.1 shows an intelligent language tutoring systems framework with an adaptive model.
The first real Arabic intelligent language tutoring system was produced. It was called the Arabic ICALL (Arabic Intelligent computer-assisted language learning), keeping in mind the end goal to instruct Arabic for elementary schools understudies utilizing propelled natural language processing methods (morphological and language structure analysers). The feedback framework determines input by contrasting the answer of the understudy alongside the perfect answer that is created by the framework. The framework makes it simple for the understudies to amend the info sentence without anyone else’s input through permitting them to find the mistake made by them (for instance, the framework helps the understudies to commit utilization of their own errors).
Different Arabic ICALL frameworks were missing to have profound error examination, advanced mistake handling, and quick reaction; the reasons that necessitated the build-up an effective mistake analyser as a key part towards upgrading Arabic ICALL frameworks (Lundberg 2001). The acclaimed NLP frameworks include various analysers that are controlled by the students. Morphological analysers are used to investigate the ranges of solutions to a multi-faceted set of problems. The sets of problems are usually non-quantifiable and complex in nature. The morphological analysers normally gives a breakdown of the systems into segments; for instance, filtering the important components in order of their importance and solving the simplified system in order to generate the required models. The created framework offers an open door for online learners to rectify the sentences freely which empowers the learner to figure out where his/her error is (Farghaly & Shaalan 2009).
The ways to deal with the utilization of models have customarily been generative, consequently filtering the models into code artefacts in the process of improvement. Nonetheless, such procedures are based on two principles. The first one is that the progressions are constantly presented by engineers, inside the improvement environment, and the second principle is that a full incorporate cycle (e.g. closing down the framework) is moderate. At the point when these principles do not hold, generative methodologies may become deficient promoting the utilization of the runtime area models. The deliberate search for more elevated levels of abstractions connected with the pervasive reception of the object arranged models concentrated to a typical engineering style called the Adaptive Object-Model (AOM), which is established on a developing collection of AOM-related examples.
As examples, they, for the most part, happen not as reusable segments but rather as saw reflections inside the outline of every specific framework. Structures are both reusable outlines and implementations that organize the collaboration between the centre elements of a framework. While they set up part of the framework’s conduct, they are intentionally open to specialization by giving hooks and specialization points. The system directs the engineering of the fundamental framework, characterizing its general structure, key obligations of every segment, and the primary string of control. It catches the design choices regular to its application space, therefore stressing the outline reuse over code reuse. Designs vary from structures since they are more unique, they have littler building components, and are less particular (Yassine, Paolo & José-Miguel 2007).
Then again, the statistical intelligent language tutoring systems framework that the paper utilised is the Ling Pipe. It is an open source application that uses managed learning for the intelligent language tutoring systems framework in which it relies on upon the Hidden Markov Model (HMM) program (software) as an element recognizer (Yassine, Paolo & José-Miguel 2007).
The HMM program plans to locate the ideal label grouping. The HMM model can be described as a sub-set of a statistical pattern. In this case the systems that are supposed to be modelled are hidden and cannot be observed. In some instances where there are simpler HMM models, the observer can view the states directly. The HMM models that are hidden are mostly applied in speech writing and other forms of communication. The Arabic language is supported by LingPipe framework. The LingPipe framework can execute two categories of tasks, for instance, filtering subjective phrases from objective phrases, and filtering positive feedback from negative feedbacks in reviews.
Auto-tutor is a computer based trainer that follows the course schemes and training approaches of a real human guide by means of a conversation with the learner utilizing the natural language. This was first accomplished by a team of researchers who were working at the Memphis University. The learners are trained about the computer proficiency course. Auto-tutor has been designed in continuous steps, where the most recent one has a 3D intelligent interface and has been actualized utilizing visual NET and C++. The Auto-tutor framework requests from the student a couple of testing questions that need a division of right replies. Every request in the Auto-tutor is attached with a particular set of interests, for instance, perfect answers and wrong replies that are put away in an educational programs script.
Auto-tutor has been processed to have the potential to rectify the wrong replies and give precise information to the student. The auto-tutor is equipped for appraising the students’ solutions and matches it with the requests and interpretations. Electronic intelligent language tutoring systems in German tutor was presented as an intelligent language tutoring systems framework that has been built to structure the sentence composition and advance it for conveying a course in German by means of the internet. The learner’s model is involved in updating every one of the learners’ profiles. It also provides the students with clever information that is suited to their education. Productivity has been achieved through the powerful plan of the framework, as demonstrated in the model above, where the user cooperates with the tutor, through an adaptive model.
The LSA processes the likeness in between any two sections of words, sentences, passages or records. Furthermore, the LSA infers relationships of anticipated sound use of words in a conversation. LSA can separate different students’ levels in the auto-tutor model. The etymological (what has been designed) and semantical (what was anticipated) levels are one of the basic tests in the intelligent language tutoring systems frameworks. Case in point, a few words have various uses in various combinations while many words could have equivalent importance; where LSA could handle these issues. Certainly, LSA has a couple of hindrances, for instance, the weakness to see a contradiction and encoding the set of words.
Evaluation
This Section talks about the establishment of the directed examinations with respect to the intelligent language tutoring systems frameworks, the principle results picked up by conducting the investigations and a broad examination of the outcomes. Numerous analysts have been contributing to the advancement of Arabic dialect in natural language processing. The results of such explorations have been used in executing an Arabic intelligent language tutoring system. A model framework that uses master frameworks innovation is created which speaks to Arabic language structure in Prolog as production principles.
The intelligent language tutoring systems assumed a critical part in reproducing the face-to-face coaching with the learners. The natural language processing concentrates on how PCs decipher and handle the human regular dialect (either content or discourse) with a specific end goal to perform supportive applications. The intelligent language tutoring systems by consolidating the natural language processing systems empower them to have the ability to assess and handle the student’s information message and give pedagogical criticism. In this manner, Arabic ILTSs are still in their underlying stages contrasted with the work done on different dialects, for example, English and Germany, which we can profit by the broad examination done in this area.
The Arabic offers large portions of its qualities with Semitic and other rich dialects. We have shown parts of Arabic dialect in this connection alongside a few troubles that could experience the advancement of the natural language processing frameworks in general and the intelligent language training systems specifically. Utilizing the intelligent language training systems as a part of the instructive field makes it simple to find the student’s mistake and give a prompt criticism to him/her alongside identifying the source of the blunder (which is a noteworthy objective in the configuration of ILTS). We endeavour in this paper to show the improvement of the intelligent language tutoring system for the most part, and a committed area has been particularized for the advancement of the Arabic intelligent language tutoring system that even now is unable to develop.
The projected structure was tested in a learning environment since it has the capacity to identify some syntactic errors in Arabic. Another master framework was suggested that could be used as an apparatus in developing the standards of Arabic punctuation which thus could help in building Arabic natural language processing frameworks.
The principal Arabic language structure checker, called Arabic GramCheck, was suggested that its execution outflanks the Arabic sentence structure checker installed with Microsoft word tools. Arabic GramCheck has recognized fundamental issues and difficulties when adding to a syntax checker for Arabic. Arabic GramCheck is able to analyse refined syntactic mistakes and recommends feedback for them. The Arabic learners provide an indirect feedback, whereas the Arabic language learners provide a direct feedback.
Experimental Setup
Be that as it may, a few parameters should be given toward the starting. The principle parameters are the registry of the corpus in the PC, the gazetteers if they will be relevant or not, the various assortments of parameters, whether they are considered or not, and the n-gram size (D’Mello & Graesser 2013).
An assortment of parameters refers to the various collections of factors that factors that determine the suitability and effectiveness of the intelligent language tutoring systems framework. Consequently, the comment set considered are the individual, locality and company. The measure of n-gram that the study took into consideration is 8. The 6-fold cross-acceptance is connected to assess the execution and the vigour of the model. Concerning assessment lattices, the study utilized exactness, review and F-measure to assess the execution of both frameworks.
There is a blueprint of the intelligent language tutoring systems frameworks courtesy of the support vector machine (SVM) strategy to manage the Arabic reports (Heift & Schulze 2007). The scientists have concentrated on the effects of the components on the execution of the intelligent language tutoring systems structure when the coordinated vernacular is Arabic. The sorts of components are incidental parts, lexical components, morphological components, and syntactic components.
The appraisals of these segments are addressed by a vector for each word despite its class (Heift & Rimrott 2008). Leech (2007) has coordinated an evaluation of three managed learning strategies that are used for the Arabic intelligent language tutoring systems. The three systems are the SVM, extreme entropy, and restrictive random field. He likewise examined the effect of components determination and learning designs on the execution of an Arabic intelligent language tutoring systems system. The results show that applying the contingent random field methodology using a plan of various elements, which joins morphological and lexical highlights among various components, attains the highest F-measure which is greater than 83%.
Experimental Results
The study has explored the principle-based framework physically with regard to the interpreted form of the ANERcorp (for instance, the best quality level corpus). As per these outcomes, the most noteworthy F-measure of 0.403 is accomplished by recognizing the person’s name substances, then the organization’s name elements that have the F-measure of 0.321, and last the location’s name elements that have the F-measure of 0.321.
In a statistical investigation of paired grouping, the F1-score, also known as the F-score or F-measure, is an assessment of a test’s precision. It contemplates both the precision (p) and the review (r) of the test to register the score. Precision (p) is the quantity of right positive results divided by the quantity of every single positive result, and recall (r) is the quantity of right positive results divided by the quantity of positive results that ought to have been sent back.
The F1-score is translated as a weighted average of the (p) and (r), in which the F1-score can achieve a value of 0 or 1. The F-score is regularly utilized as a part of the field of data recovery for measuring and report grouping. Prior works concentrated essentially on the F1-score, yet with the expansion of extensive scale internet searchers, the performance objectives changed to place more accentuation on either accuracy or review. The F-score is likewise utilized as a part of machine learning. The F-score has been generally utilized as a part of the NLP literature, for example, the assessment of NER and word division (Heift & Schulze 2007). The formula for calculating the F-score is:
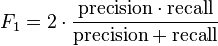
Discussion of results
Be that as it may, the Arabic gazetteers utilized as a part of the framework appear to be exceptionally constrained and do not spread a large portion of the basic named elements. Another issue that reveals itself with regards to the individual’s names is the distinguishing proof of any word that implies or alludes to a man, for example, Iranian and individual or a gathering of individuals, for example, Lebanese and the public as an individual named substance.
Another essential matter is that at whatever point a relational word is associated with a named substance, the framework cannot distinguish it while the same named substance can be perceived by the framework on the off chance that it is not associated with any relational word. So as to comprehend these issues in the tenet based intelligent language tutoring systems framework with regards to the Arabic dialect, various strategies and proposals are recommended. The first is to enhance the Arabic gazetteers by covering vast arrangements of the most recent and regular named substances and incorporating them in the gazetteers.
The gazetteers should be overhauled frequently. Also, an Arabic morphological analyser can be utilized as a part of the framework to diminish the over-reliance on the gazetteers in the assignment of the intelligent language tutoring systems. The third is to utilize the arrangements of catchphrases to encourage the success of the framework.
These watchwords are prone to be ahead of or behind the named elements, and a catchphrase can be of various sorts, for example, names, verb or descriptive word. Subsequently, having separate records for every sort will be suitable keeping in mind the end goal to use these watchwords effectively and each named element sort needs its own arrangements of catchphrases. The catchphrases will help in finding and ordering the named substances accurately. The fourth is to adjust the guidelines written in the framework so they can function adequately with the morphological analyser yield and the arrangements of catchphrases.
As indicated by the past perceptions, taking into account the morphological components of the Arabic content might upgrade the execution in the measurement based intelligent language tutoring systems frameworks. Additionally, having substantial explained Arabic corpora will offer to create a huge assistance with factual based intelligent language tutoring systems frameworks. Consequently, making the Arabic handling assets when all is said in done and the Arabic corpora specifically accessible for nothing should improve and encourage the examination in Arabic intelligent language tutoring systems area.
Conclusion and Future Prospects
The primary point of the study was to investigate the essential scopes of intelligent language tutoring systems frameworks. The point of the framework is to plan the NLP frameworks that go for educating and surveying the ability of the students. The use of the intelligent language tutoring systems frameworks in direction makes it easy to investigate the leaner’s mix-up and give valuable info and wipe out the sources of mistakes. There are special dialects mentoring frameworks that have been portrayed in this paper.
It must be noticed that authoring systems are very not the same as intelligent language tutoring systems frameworks as they just enable the creator to address his data in common dialect without relying upon any intelligent programming. Since adopting any new dialect is a testing task, the part of this paper is in this way, to give the new bits of knowledge of intelligent language tutoring systems frameworks that eliminate the difficulties. To the best of the paper’s advantage, the intelligent language tutoring systems frameworks have not yet been overviewed generally; this has provided the system to lead this study.
Arabic natural language processing has been developed quickly; a lot of utilizations have been produced in various spaces, for example, information recovery, data mining, machine translation, transcript to dialogue, and tutoring systems (which is the fundamental centre of this paper). To the extent Arabic is concerned, scholars must to consider the difficulties and qualities of the language, for example, an uncertainty which is a noteworthy issue in enhancing that needs to comprehend when creating Arabic natural language processing frameworks.
The culture and the rich history of the Arabs have catalysed the fame and popularity borne by the Arabic language. The language is now spoken in every continent of the world. It is estimated that the language has an overall reach of at least 300 million people from all corners of the world. Discretization takes on an essential part improperly declaring and disambiguating the Arabic words (Di Donato, Clyde & Vansant 2004).
The common Arabic dialect being utilized has been grouped into three classifications. The main class is the customary Arabic or Qur’anic Arabic. It is the perceived structure that had been used for quite a while as the standard language of Islam. The second classification is the present day standard Arabic. It is the lingo used by media and schools and colleges. At last, the third class is the everyday Arabic. It is the easy-going step by step vernacular by the Arabs (Harbusch et al. 2008).
The handling of the Arabic normal dialect has been created rapidly; a considerable measure of usages have been delivered in different spaces, for instance, data recovery, information sourcing, machine interpretation, transcript to dialog, and mentoring frameworks. In line with the Arabic dialect, researchers need to consider the challenges and characteristics of the dialect, for instance, an instability which is an essential problem in the teaching process that requires being grasped while making the handling systems for the Arabic dialect (Heift & Nicholson 2001). For the purpose of this paper, where the main focus was the intelligent language tutoring systems, picking confused investigation of the learner’s data may provoke misguided determination of slip-ups or issuing of criticisms.
Arabic natural language processing has been developed quickly; a lot of utilizations have been produced in various spaces, for example, information recovery, data mining, machine translation, transcript to dialogue, and tutoring systems. To the extent Arabic is concerned, scholars must consider the difficulties and qualities of the language, for example, an uncertainty which is a noteworthy issue in enhancing that needs to be comprehended when creating Arabic natural language processing frameworks.
For our situation, where we are worried about intelligent language tutoring systems, picking mistaken examination of the learner’s information may prompt off base determination of mistakes or issuing of feedbacks. Auto-tutor has been programmed to have the capacity to adjust the misguided judgments and give a proper input to the learner. For the Auto-tutor to be equipped for assessing the learners’ answers and equal it with the desires and misinterpretations, latent semantic analysis has been used as the example coordinating strategy. Be that as it may, a lexicon-syntactic procedure is likewise utilized as a part of a request to conquer the impediments of latent semantic analysis by means of considering syntactic data while assessing learners’ answers.
Many scholars have tended to the imperative issue of morphological disambiguation of amended elucidations of mixed up Arabic verbs that have been composed by novices to intermediary second language learners. An Arabic intelligent language tutoring system has been created that can break down the students’ answers through investigating every info from the student and afterward produce all the conceivable examination. All the produced examination will be sent to the disambiguation framework with a specific end goal to anticipate the right investigation as indicated by morphological components. The rectified examination will be utilized to distinguish the understudy’s errors that can be raised from his/her information, and afterward, Arabic intelligent language tutoring systems will analyse these mix-ups (i.e. particularly recognizing the mistake source and give a quick particular input).
There has been an impressive advancement in the field of Arabic intelligent language tutoring systems on account of the endeavours made by scholars in the Arabic talking world. However, the exploration group has seen a decent advancement in outlining and actualizing the Arabic intelligent language tutoring systems there are a few issues which are either overlooked or mostly comprehended because of the absence of phonetic assets and apparatuses which make a basic impediment with regards to Arabic mistake diagnosis specifically. Intelligent language tutoring systems has assumed a huge part in recreating the balanced coaching with understudies. Natural language processing concentrates on how PCs decipher and handle the human regular dialect (either content or discourse) with a specific end goal to perform accommodating applications.
The intelligent language tutoring systems by joining the natural language processing methods empower them to have the ability to assess and handle the learner’s info message and give pedagogical criticism. Arabic offers a large portion of its qualities with Semitic and morphologically rich dialects. We have represented parts of Arabic dialect in this setting alongside a few challenges that could experience the advancement of natural language processing frameworks all in all and intelligent language tutoring systems specifically.
Utilizing intelligent language tutoring systems as a part of the instructive field makes it simple to find the leaner’s blunder and give a prompt criticism to him/her alongside allotting the mistake source (which is a noteworthy objective in the configuration of intelligent language tutoring systems). All of the intelligent language tutoring systems that consolidated a dialog with learner has been incorporated in English when contrasted with different dialects. It is valuable to fuse other hard to learn dialects, for example, Arabic, keeping in mind the end goal to investigate more in the dialects’ components while managing the learner.
Recommendations for further research
The main aim of the study was to explore the important ranges of intelligent language tutoring systems. The aim of the system is to formulate the natural language processing systems that aim at teaching and assessing the capability of the students. This segment recommends some exploration areas which have not been explored in the present research area and require more consideration from scholars:
- There should be further research should focus on formulating ILTS frameworks that deal with voice dialogues which can breaking down the information content from the learner.
- Additional research should be done on concept grid to be used as a learning instrument.
- A great research opportunity could be developed from this paper which is building an online intelligent language tutoring systems native speakers with a specific end goal to come to a more extensive scope of individuals over the internet.
References
Acosta, D & Anja, W. 2015, Global Migration: Old Assumptions-New Dynamics, Praeger, Santa Barbara.
Chowdhury, G 2003. ‘Natural language processing’, Annual review of information science and technology, vol. 37, no. 1, pp. 51-89.
D’Mello, S & Graesser, A 2013, Design of Dialog-Based Intelligent Tutoring Systems to Simulate Human-to-Human Tutoring, Springer, New York.
Di Donato, R, Clyde, M & Vansant, J 2004, Deutsch, Na Klar! An Introductory German Course, McGraw Hill, Boston.
Farghaly, A & Shaalan, K 2009. ‘Arabic natural language processing: Challenges and solutions’, ACM Transactions on Asian Languag Information Processing (TALIP), vol. 8, no. 4, pp. 14-18.
Harbusch, K, Itsova, G, Koch, U & Kuhner, C 2008, ‘The Sentence Fairy: A natural-language generation system to support children’, Computer Assisted Language Learning, vol. 2, no. 1, pp. 14-18.
Heift, T & Nicholson, D 2001, ‘Web delivery of adaptive and interactive language tutoring’, International Journal of Artificial Intelligence in Education, vol. 1, no. 2, pp. 310-325.
Heift, T & Rimrott, A 2008, ‘Learner responses to corrective feedback for spelling errors in CALL’, System, vol. 3, no. 6, pp. 196-213.
Heift, T & Schulze, M 2007, Errors and intelligence in CALL, Parsers and pedagogues, Routledge, New York.
Jung, S & VanLehn, K 2010, Developing an intelligent tutoring system using natural language for knowledge representation, Springer, Berlin.
Leech, G 2007, Teaching and language corpora: A convergence, Longman, London.
Lundberg, C 2001. ‘Toward Theory More Relevant for Practice’, Current Topics in Management, vol. 6, no. 1, pp. 15-24.
Miller, R 2000. ‘How Culture Affects Mergers and Acquisitions’, Industrial Management, vol. 2, no. 1, pp. 8-8.
Monz, C & de Rijke, M 2001, Light-weight entailment checking for computational semantics, Springer, New York.
Nagata, N & Swisher, M 2005, ‘A study of consciousness-raising by computer: The effect of metalinguistic feedback on second language learning’, Foreign Language Annals, vol. 28, no. 1, pp. 337-347.
Nerbonne, A 2003, Computer-assisted language learning and natural language processing, Oxford University Press, Oxford.
Peters, M, Weinberg, A & Sarma, N 2009, ‘To like or not to like! Student perceptions of technological activities for learning French as a second language at five Canadian institutions’, Canadian Modern language Review, vol. 65, no. 2, pp. 869-896.
Rosa, M & Leow, P 2004, ‘Computerized task-based exposure, explicitness, type of feedback, and Spanish L2 development’, The Modern Language Journal, vol. 88, no. 2, pp. 192-216.
Yassine, B, Paolo, R & José-Miguel, B 2007, ANERsys: An Arabic Named Entity Recognition System Based on Maximum Entropy, Springer, Berlin.
Yazdani, M 2016. ‘Intelligent tutoring systems survey’, Artificial Intelligence Review, vol. 1, no. 1, pp. 43-52.